
Um Ihre sensiblen Daten schützen zu können, müssen Sie wissen, welche Daten sensibel sind und wo sie liegen.
Definition Datenklassifizierung
Datenklassifizierung ist der Prozess, in dem strukturierte oder unstrukturierte Daten analysiert und aufgrund der Dateityps und ihres Inhalts in Kategorien eingeordnet werden.
Bei diesem Prozess werden Dateien im Hinblick auf bestimmte Zeichenfolgen untersucht, ungefähr so, als wollten Sie alle Verweise auf „Chili-Sauce“ in Ihrem Netzwerk finden. Oder als ob Sie wissen wollten, wo alle geschützten HIPAA-Daten in Ihrem Netzwerk gespeichert sind. Oder als ob Sie sich auf neue Datenschutzverordnungen vorbereiten wollten und alle personenbezogenen Daten in Ihren Datenspeichern identifizieren müssten.

Die Datenklassifizierung erfolgt überlicherweise auf Basis eines Datei-Parsers in Kombination mit einem Analysesystem für Zeichenfolgen. Mit einem Datei-Parser kann die Datenklassifizierungs-Engine die Inhalte mehrerer Dateitypen lesen. Danach werden die Daten in den Dateien mithilfe einer systematischen Zeichenfolgenanalyse mit den festgelegten Suchparametern abgeglichen.
RegEx – was für regulärer Ausdruck steht – ist ein recht weit verbreitetes Zeichenfolgenanalysesystem, das Merkmale für Suchmuster festlegt. Wenn ich beispielsweise alle VISA-Kreditkartennummern in meinen Daten finden wollte, sähe die RegEx folgendermaßen aus:
\b(?<![:$._’-])(4\d{3}[ -]\d{4}[ -]\d{4}[ -]\d{4}\b|4\d{12}(?:\d{3})?)\b
Diese Folge teilt dem RegEx-System mit, dass wir nach einem Muster mit einer vierstelligen Zahl mit einer 4 am Anfang suchen, gefolgt von einem Bindestrich und einer zweiten vierstelligen Zahl und… Sie sehen, wie es geht. Nur eine Zeichenfolge mit Zeichen, die zum RegEx passt, führt direkt zu einem positiven Ergebnis.
Und obwohl es zwar einige Parallelen gibt, ist Datenklassifizierung nicht dasselbe wie Datenindexierung. Bei der Klassifizierung wird nach Kennzeichen auf der Grundlage von Mustern gesucht und eine Datei-Liste sowie die Anzahl der für das jeweilige Muster gefundenen Treffer ausgegeben. Diese Dateien werden nicht unbedingt indexiert. Eine Indexierung macht Suchen möglich, und Sie müssen diese Treffer durchsuchen, um Auskunftsanträge betroffener Personen und Anträge im Zusammenhang mit dem Recht auf Vergessenwerden bearbeiten zu können.
Gründe für die Datenklassifizierung

Das Center for Internet Security (CIS), das eine ganze Sektion für den Schutz durch Datenklassifizierung vorgesehen hat, meint, dass Datenklassifizierung wichtig ist, weil „die Angreifer bei mehreren spektakulären Datenschutzverletzungen in den letzten zwei Jahren Zugriff auf sensible Daten erlangen konnten, die auf denselben Servern mit identischer Zugriffsstufe wie wesentlich weniger wichtige Daten lagen.“
Neben Datenschutzaspekten gibt es mehrere weitere Gründe dafür, einen Datenklassifizierungsprozess einzuführen:
- Identifizieren von sensiblen Dateien, geistigem Eigentum und Geschäftsgeheimnissen
- Sichern (und Sperren) kritischer Daten
- Nachverfolgen regulierter Daten, um die Anforderungen von Vorschriften wie HIPAA, PCI oder DSGVO zu erfüllen
- Optimieren von Suchmöglichkeiten durch Datenindexierung
- Erkennen statistisch signifikanter Muster oder Trends im Datenbestand
- Speicheroptimierung durch Identifizierung von redundanten oder verwaisten Daten
Der Datenklassifizierungsprozess: 4 Schritte
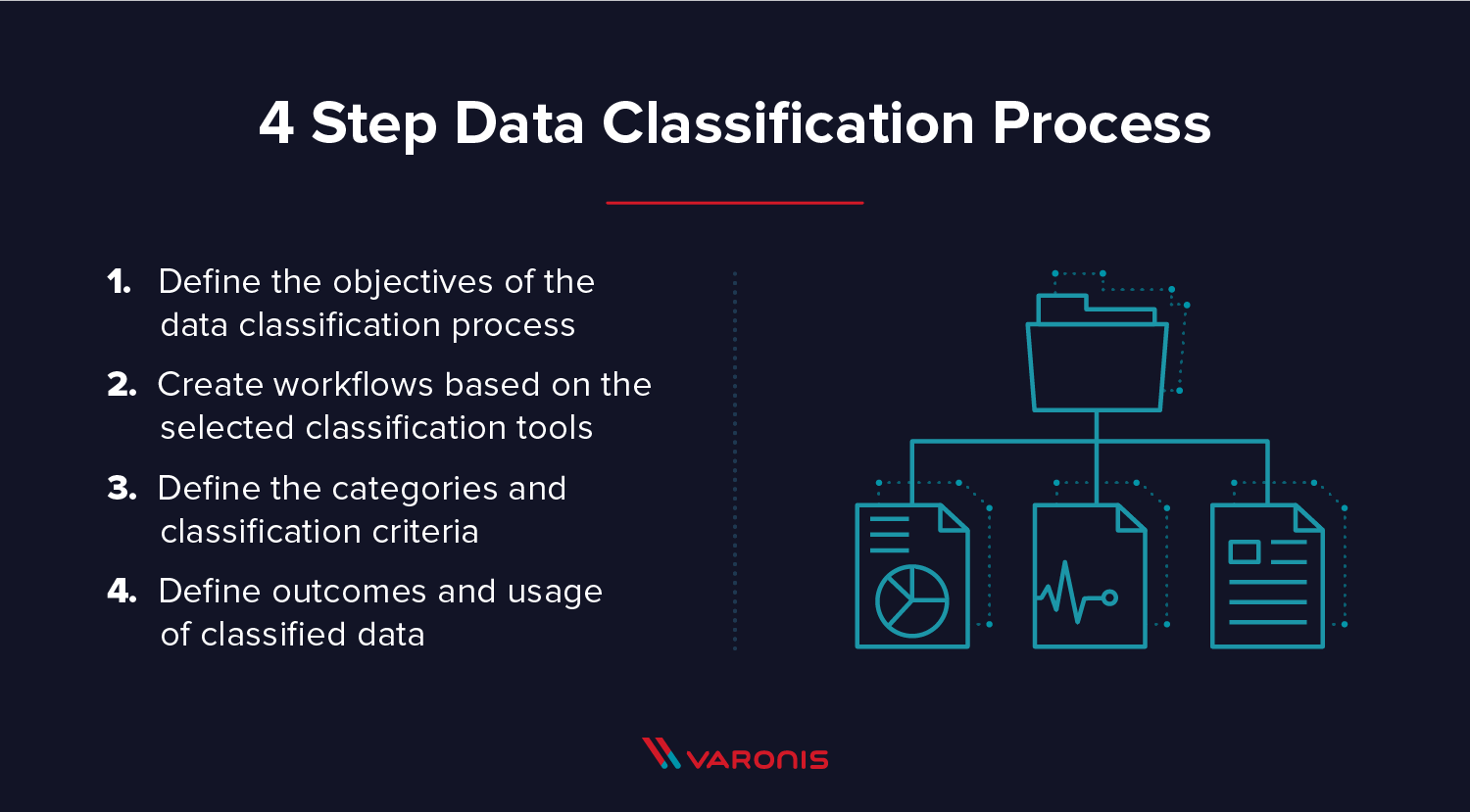
Datenklassifizierungsprozesse unterscheiden sich leicht untereinander, je nach Vorgabe für das Projekt. Für jedes Datenklassifizierungsprojekt ist für die Verarbeitung der erstaunlichen Datenmengen, die täglich im Unternehmen anfallen, eine Automatisierung unverzichtbar. Im Allgemeinen gibt es einige omnipräsente Kriterien, die beim Erstellen eines jeden Datenklassifizierungsprozesses benötigt werden:
- Legen Sie die Ziele für den Datenklassifizierungsprozess fest. Wonach suchen Sie? Warum?
- Erstellen Sie Arbeitsabläufe auf Basis der ausgewählten Datenklassifizierungstools. Wie funktioniert der Klassifizierungsprozess? Wurde ein Prozess zum Scannen neuer Daten eingerichtet? Gibt es einen Prozess zum Erstellen neuer Klassifizierungskriterien?
- Legen Sie die Kategorien und Klassifizierungskriterien fest. Nach welchen Arten von Daten sollten Sie suchen? Mit welchen Prozess werden Sie die Klassifizierungsergebnisse validieren?
- Legen Sie fest, welche klassifizierten Daten erfasst und wie sie verwendet werden. Wie werden die Ergebnisse organisiert – und wie werden geschäftliche Entscheidungen auf der Grundlage dieser Ergebnisse getroffen?
Tipps für die Datenklassifizierung
- Nutzen Sie automatische Tools um große Datenmengen schnell zu verarbeiten.
- Nutzen Sie RegExes und Luhn: Erstellen Sie individuelle Klassifizierungsmuster oder führen Sie Software ein, die Ihnen die schwere Arbeit abnimmt.
- Validieren Sie Ihre Klassifizierungergebnisse: Falsche Treffer mag niemand.
- Überlegen Sie sich, wie sich Ihre Ergebnisse am besten nutzen lassen und führen Sie eine Klassifizierung für alles – vom Datenschutz bis zur Business Intelligence – ein.
Datenklassifizierungs-FAQ
Was macht Varonis bei der Datenklassifizierung anders?
Varonis verfügt über 400 fertig konfigurierte RegExes, um alle Arten von PII-, PHI- und DSGVO-Daten zu erkennen, wobei eine vollständig nach Kundenbedarf einstellbare Klassifizierungs-Engine hilft, die Sie für jeden geschäftlichen Zweck konfigurieren können. Varonis überwacht direkt ab Installation 60 Dateitypen (einschließlich Dokumente, Spreadsheets und weitere) und identifiziert neue Daten, die erneut untersucht werden müssen (ohne den Gesamtprozess neu zu starten), um neue und kürzlich hinzugefügte sensible Dateien zu erfassen, wie z. B.:
- Personenbezogene Daten: Kreditkartennummern, Reisepassnummern, Führerscheinnummern, Sozialverscherungsnummern, IBAN und weitere
- Finanzunterlagen
- Sicherheitsdateitypen (.cer, crt, p7b usw.)
- Regulierte Daten (DSGVO, HIPAA, PII, PHI, PCI, Sabanes Oxley, GLBA usw.)
Die Varonis Data Classification Engine kann ca. 100 GB Daten pro Stunde verarbeiten (vorbehaltlich der passenden Hardware- und Netzwerkkapazität) und umfasst rigorose Prüfungen auf falsche Treffer, mit denen das Arbeitsvolumen bei der Analyse der Klassifizierungsergebnisse reduziert wird. Zum Beispiel ist nicht jede 16-stellige Zahlenkette eine Kreditkartennummer, un Varonis erkennt den Unterschied.
Was kommt nach der Datenklassifizierung?
Varonis reichert die Klassifizierung mit Kontextinformationen an. Varonis identifiziert nicht nur die Daten, nach denen Sie suchen, sondern zeigt Ihnen auch, wer auf diese Daten zugreifen kann – und wer das tatsächlich tut. Nachdem Sie sensible Daten identifiziert und klassifiziert haben, können Sie diese bearbeiten, durch Kennzeichnen, Sperren von Berechtigungen, Überwachen von Zugriffen, Meldung verdächtiger Aktivitäten und Erfüllen von aufsichtsrechtlichen Vorgaben, wie dem Recht auf Vergessenwerden. Mit der Varonis Data Classification Engine können Sie Ihre sensibelsten und wichtigsten Daten gegen unbefugte Zugriffe, zufällige Datenlecks und Datenschutzangriffe verteidigen.
Beobachten Sie bei einer 1:1-Demo die Data Classification Engine in Aktion.
What you should do now
Below are three ways we can help you begin your journey to reducing data risk at your company:
- Schedule a demo session with us, where we can show you around, answer your questions, and help you see if Varonis is right for you.
- Download our free report and learn the risks associated with SaaS data exposure.
- Share this blog post with someone you know who'd enjoy reading it. Share it with them via email, LinkedIn, Reddit, or Facebook.



-1.png)

