
Alle Mitglieder der Infosec-Community warten mit Spannung darauf, dass Ponemon in den frühen Sommermonaten seine jährliche Analyse der Kosten von Datenschutzverletzungen veröffentlicht. Was wäre das für ein Sommer, in dem wir nicht durch die Ponemon-Analyse scrollen würden, um uns die durchschnittlichen Kosten der Vorfälle des letzten Jahres, die durchschnittlichen Kosten pro Datensatz und die detaillierten Branchenanalysen anzuschauen? All das findet man im aktuellen Bericht. Aber dann tat Ponemon etwas ganz Erstaunliches.
Die armen Teufel, die sich durch meine Posts über die Kosten von Datenschutzverletzungen gekämpft haben, erfuhren, dass die hier verwendeten Datensätze nicht normal sind. Das meine ich wörtlich. Sie entsprechen nicht einer Standardnormalisierung oder Glockenkurve. Wir wissen auch aus detaillieren Untersuchungen, dass die Datenpunkte durch „schwere Enden“ verzerrt sind und sich besser durch Potenzgesetze darstellen lassen.
Was hat das mit der Kostenanalyse von Ponemon zu tun?
Ponemon hat das Problem sich mit verzerrten Daten auseinandersetzen zu müssen, dadurch vermieden, dass es die Ausreißer abgeschnitten hat – Datenschutzverletzungen mit mehr als 100.000 betroffenen Datensätzen werden nicht berücksichtigt. Sicher, es gehen ein paar Informationen verloren, aber die Statistiken werden viel aussagekräftiger für (die meisten) Unternehmen, die nicht am Long Tail der Kurve angesiedelt sind.
Monströse Datenschutzverletzungen sind teuer. Sehr teuer.
Halten Sie sich fest: Für das Jahr 2018 hat Ponemon begonnen, sich den Schwanz des Drachen genauer anzuschauen. Sie haben eine Analyse von Mega-Datenschutzverletzungen mit über einer Million betroffenen Dateien eingeschlossen.
Lassen Sie uns als erstes die schlechten Nachrichten aus dem Weg schaffen. Weil Ponemon für die Stichprobe von Mega-Datenschutzverletzungen nur 11 Unternehmen hatte, haben sie eine Monte-Carlo-Analyse durchgeführt. Das ist eine elegante Ausdrucksweise dafür, dass sie einige Annahmen über einige Parameter in ihrem Modell machen mussten, weshalb diese mit „Zufallsstichproben“ generiert wurden.
Der springende Punkt ist, dass in ihrem Diagramm der Kosten des Verstoßes vs. die Anzahl gestohlener Datensätze die Datenpunkte eine sublineare (stärker technisch betrachtet eine loglineare) Beziehung aufweisen – die Kosten wachsen langsamer als linear. Verdopple die Anzahl der gestohlenen Datensätze und die Gesamtkosten des Vorfalls sind weniger als doppelt so hoch.
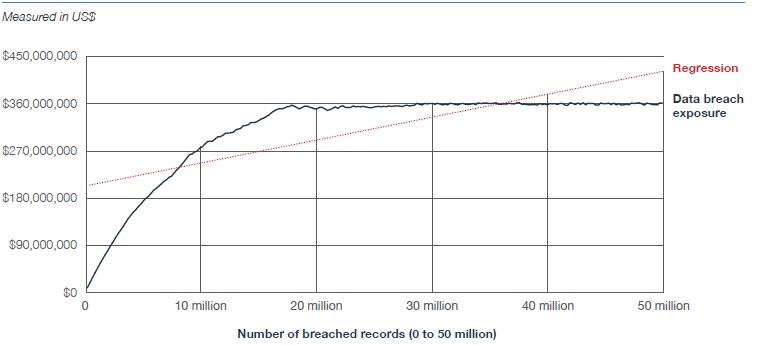
Und das ist genau das, was bereits andere Analysten im Hinblick auf die Kosten von Datenschutzverletzungen beobachtet haben. Auch ich habe in meiner Serie über die Kosten von Datenschutzverletzungen auf diesen interessanten Fakt hingewiesen – Sie können hier mehr dazu lesen.
Für CFOs und CIOs birgt diese langsam wachsende Kurve ein Quäntchen Trost. Sie besagt, dass die Kosten pro Datensatz fallen, je mehr Datensätze betroffen sind.
Das Diagramm zeigt uns indirekt, dass die Kosten für den Diebstahl von 20 Millionen Datensätzen bei ca. 18 USD pro Datensatz liegen. Bei 50 Millionen Datensätze fällt diese Kennzahl auf ca. 7 USD.
Das mag möglicherweise günstig klingen, wenn es bei einer Präsentation am Rande erwähnt wird, aber andererseits liegen die Kosten für den Diebstahl von 50 Millionen Datensätzen bei über 350 Millionen USD.
Und das ist etwas, was kein Vorstand der Welt gerne hören wird!
NetDiligence: Verifizierung im wahren Leben
Während die theoretische Analyse der Kosten von Mega-Datenschutzverletzungen interessant ist, gibt es tatsächlich einen Datenbestand, der mehr Licht auf die Kosten dieser Katastrophen im wahren Leben wirft. Dessen Existenz haben wir NetDiligence zu verdanken, einem Anbieter von Datensicherheitsanalysen, der Zugriff auf die tatsächlichen Schadensdaten von Cyber-Versicherungsgesellschaften hat.
Ich habe mir den letzten Bericht von NetDiligence für die Zeit von 2014 bis 2017 angeschaut. Er bestätigt, dass die Kosten von Datenschutzverletzungen im oberen Bereich tatsächlich sehr hoch sind.
Laut NetDiligence lagen bei den 591 Schadensfällen in ihrem Datenbestand diese Kosten im Durchschnitt bei ca. 394.000 USD. Sie berechneten außerdem den Median der Kosten bei bescheidenen 56.000 USD. Da 50 % ihrer Daten bzw. 245 Schadensfälle über 56.000 USD lagen, müssen darunter einige Monsterschäden sein, wenn der Mittelwert ungefähr beim Siebenfachen des Medians liegt. Das weist auf einen anormalen Datenbestand hin – auf den stark schwanzlastigen Kurvenverlauf, den wir üblicherweise bei Statistiken über Datenschutzverletzungen beobachten können.
Mit einer kleinen Überschlagsrechnung kann ich Ihnen einen besseren Eindruck der Megakosten vermitteln, die im Dunkeln der NetDiligence-Statistik lauern. Wenn Multiplikationen mit Durchschnittswerten leichten Schwindel verursachen, können Sie diesen nächsten Abschnitt einfach überspringen.
Die Gesamtkosten der Datenschutzverletzungen im Datensatz liegen bei ca. 233 Millionen USD (591 x 394.000). Ein zu vernachlässigender Betrag der Gesamtkosten liegt unter dem Median – maximal 56.000 x 246 bzw. ca. 14 Millionen USD. Damit bleiben und Kosten in Höhe von 219 Millionen USD über dem Median, die dann auf über 245 Schadenfälle verteilt werden. Das bedeutet, dass bei den oberen 50 % die Durchschnittskosten bei mindestens 890.000 USD liegen.
Wenn Sie noch ein paar weitere Annahmen zugrunde legen – wie ich es beispielsweise hier getan habe – ergeben sich schnell Kosten in Höhe mehrerer Millionen Dollar für Datenschutzverletzungen in den oberen Perzentilen.
Dessen ungeachtet verraten uns die Kollegen von NetDiligence in ihrer Analyse nicht allzu viele Details über die individuellen Datenschutzverletzungen. Später in ihrem Bericht deuten sie allerdings einige der extremen Kosten in ihrem Schadendatensatz an. Erkennbar werden diese in einer Tabelle, in der die Kosten nach Unternehmensgröße aufgeschlüsselt werden.
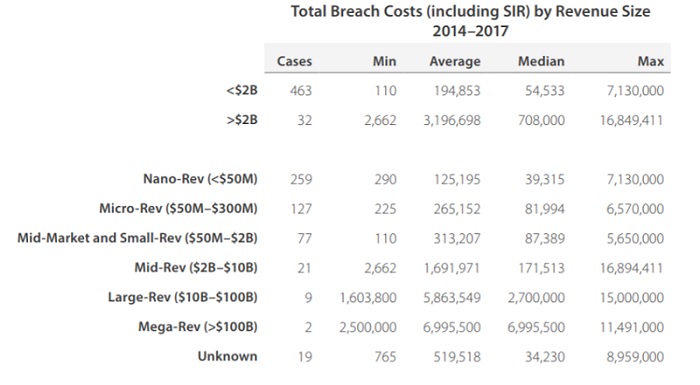
Wenn Sie sich die Spalte „Max“ anschauen, sehen Sie, dass es mehrere Vorfälle mit höheren Kosten als 10 Millionen USD gab. Das sind keine Peanuts.
Und noch etwas
Es sollte auch erwähnt werden, dass Ponemon in die Kosten der Vorfälle auch indirekte Kosten einbezieht, die stark auf der Abwanderung von Kunden beruhen. Diese Kosten werden in den Schadenmeldungen der Cyber-Versicherungen nicht sichtbar, weil diese auf harten Kosten beruhen – Anwaltshonorare, Strafzahlungen, Bonitätsüberwachung, Gegenmaßnahmen usw.
In anderen Worten: Die Kostenanalyse von Ponemon wird immer deutlich höhere Trends ergeben als die Zahlen aus tatsächlichen Versicherungsansprüchen. Allerdings sind die Kostengrößen von Ponemon vermutlich auch näher an den realen Kosten, insbesondere für größere Unternehmen. Und erst recht für börsennotierte Unternehmen, bei denen Datenschutzverletzungen die Gesamtbewertung beeinträchtigen können. Ein Beispiel wäre Yahoo.
Die zentrale Erkenntnis ist, dass die Datenschutzverletzungen in den Schlagzeilen (Equifax, Yahoo usw.) uns über das lange Ende der Kostenkurve informieren. Der Bericht von NetDiligence zeigt uns vor allem, dass es auch im mittleren Kurvenverlauf teure Datenschutzverletzungen mit Kosten in zweistelliger Millionenhöhe gibt. Über sie wird zwar wahrscheinlich seltener berichtet, sie treten aber häufiger auf.
Ich werde in einem zukünftigen Post noch einmal genauer auf die beiden Berichte von Ponemon und NetDiligence eingehen.
What you should do now
Below are three ways we can help you begin your journey to reducing data risk at your company:
- Schedule a demo session with us, where we can show you around, answer your questions, and help you see if Varonis is right for you.
- Download our free report and learn the risks associated with SaaS data exposure.
- Share this blog post with someone you know who'd enjoy reading it. Share it with them via email, LinkedIn, Reddit, or Facebook.



-1.png)

